Abstract
Background
In Federated Learning (FL), many existing methods assume clients’ data are i.i.d. (independently and identically distributed), enabling straightforward model-parameter averaging (e.g., FedAvg) to learn a global model. However, in real-world scenarios, data often come from different domains, sharing only the label space but differing in their distributions. This scenario is known as Federated Domain Adaptation (FDA). Under FDA, the large domain gaps across clients undermine the effectiveness of naive averaging-based approaches, making it challenging to achieve good performance both on each local domain and on out-of-domain data.
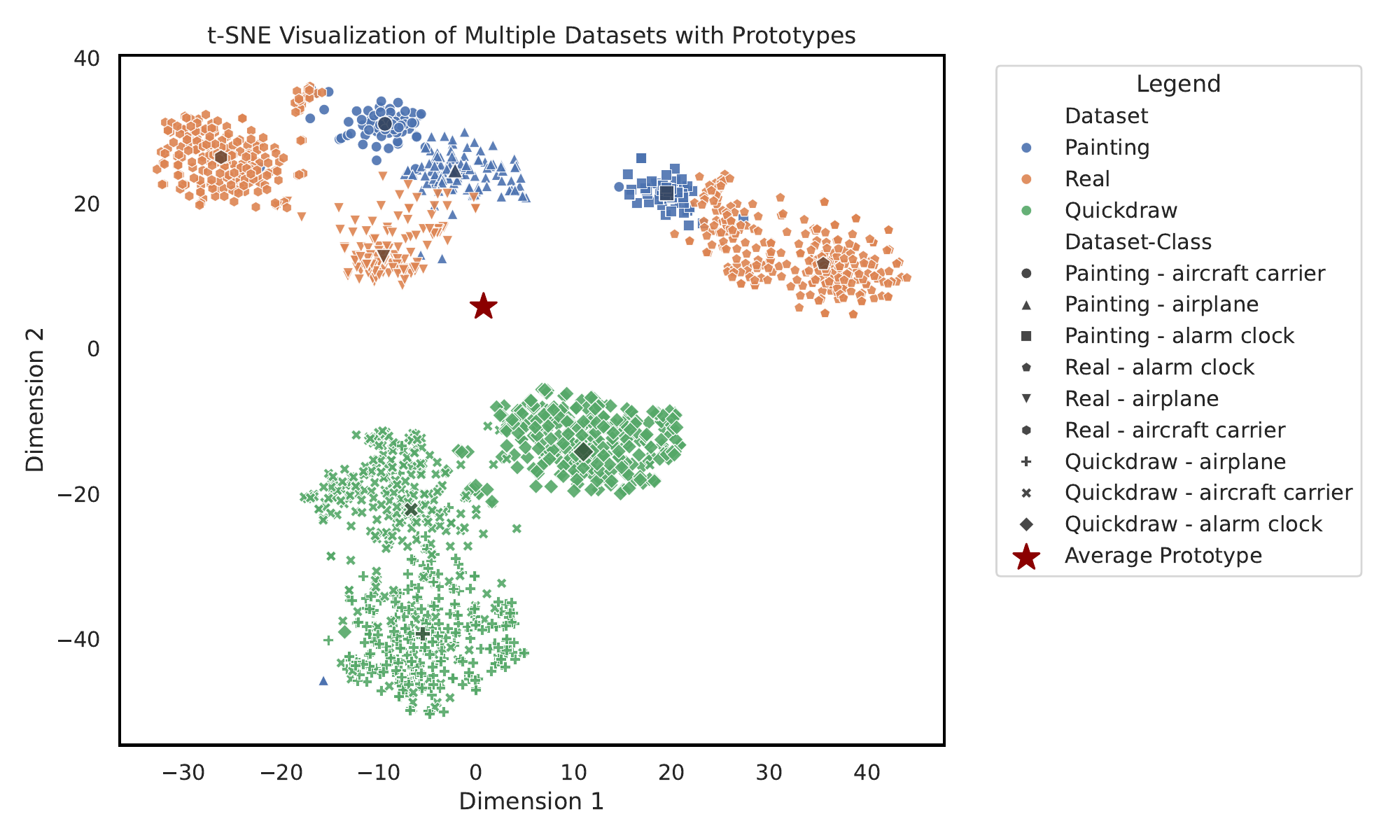
A visualization shows that the large domain gaps across clients undermine the effectiveness of naive averaging-based approaches.
Motivation
Numerous fields—such as finance, healthcare, and image recognition—require models that not only perform well on each client’s own domain (in-domain) but also generalize to other domains (out-of-domain). Traditional solutions often overfit to local domains, losing cross-domain generalization, or force an averaged global model that poorly fits each unique domain. A more effective, privacy-preserving method is needed to capture domain-specific knowledge and also aggregate insights across domains without sharing raw data.
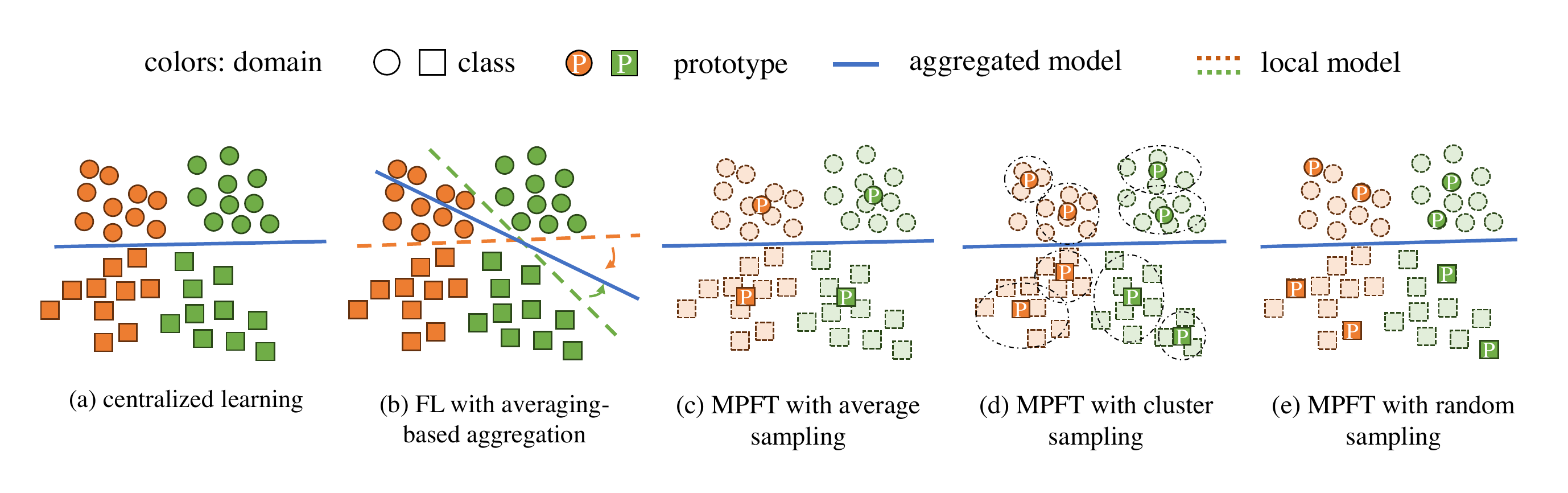
Comparison of MPFT to centralized learning and previous averaging-based FL approaches.
Problem Statement
Under FDA, each client holds data from a unique domain (but with the same label space). The goal is to jointly train a model (or local/global models) that meets two key requirements:
- Domain Knowledge Preservation (ind accuracy): Retain high accuracy on each client’s own domain.
- Domain Knowledge Adaptation (ood accuracy): Transfer knowledge learned from other domains to achieve high accuracy on out-of-domain data.
Because averaging model parameters often fails in the presence of substantial domain gaps, a new aggregation mechanism is necessary.
Methodology
The proposed framework, MPFT (Multi-domain Prototype-based Federated Fine-Tuning), addresses FDA in three main steps:
-
Prototype Generation
- Each client uses the same pretrained feature extractor to generate class-specific embeddings (i.e., prototypes).
- Different sampling strategies (mean, cluster, or random) can be chosen to capture representative embeddings of each class in each domain.
-
Global Adapter Initialization
- The server collects these prototypes from all clients, effectively constructing a “prototype dataset.”
- It then fine-tunes a global adapter on this aggregated dataset, simulating a centralized training approach without parameter averaging.
- A single communication round suffices to train this global adapter.
-
Few-shot Local Adaptation (Optional)
- If a client requires higher in-domain accuracy, it can use a small local dataset (few-shot) to further fine-tune the adapter.
- Knowledge distillation (KD) is employed to maintain global knowledge while adapting to local data, mitigating catastrophic forgetting.
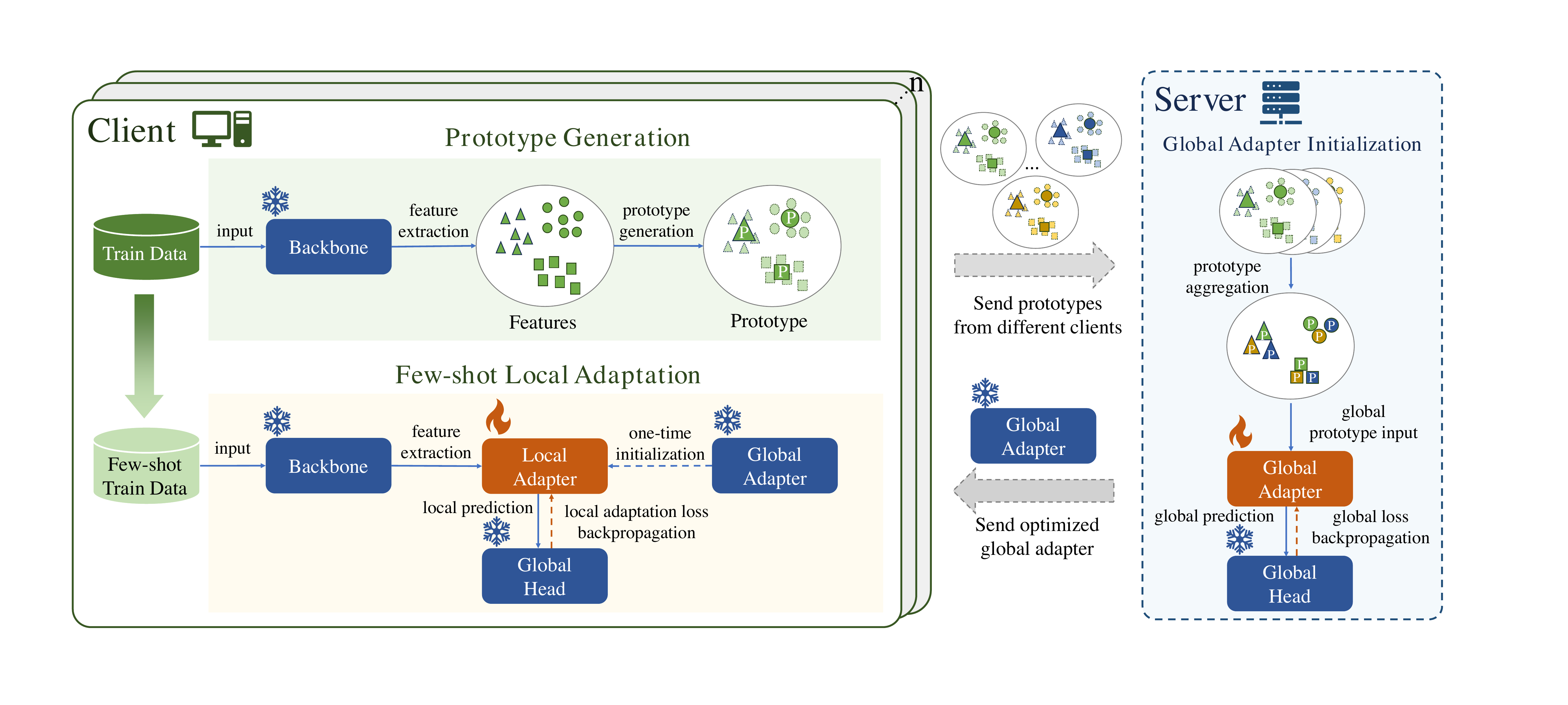 An overview of MPFT.
An overview of MPFT.
Experiment
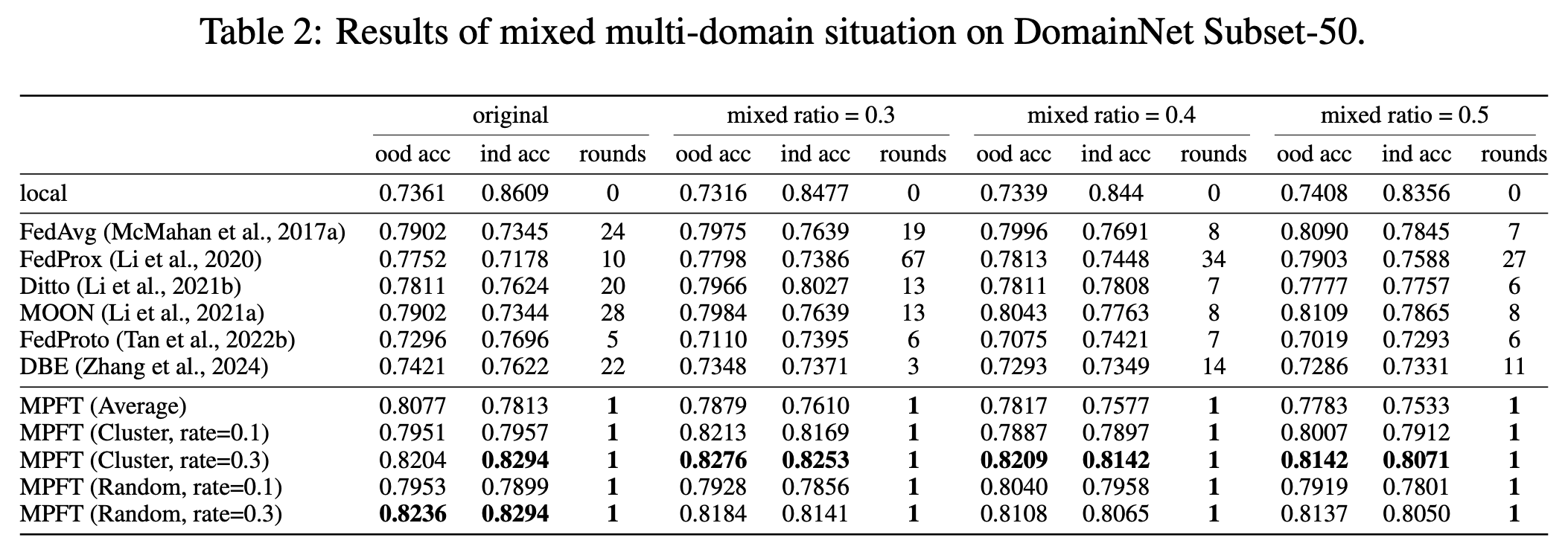
Performance on multi-domain
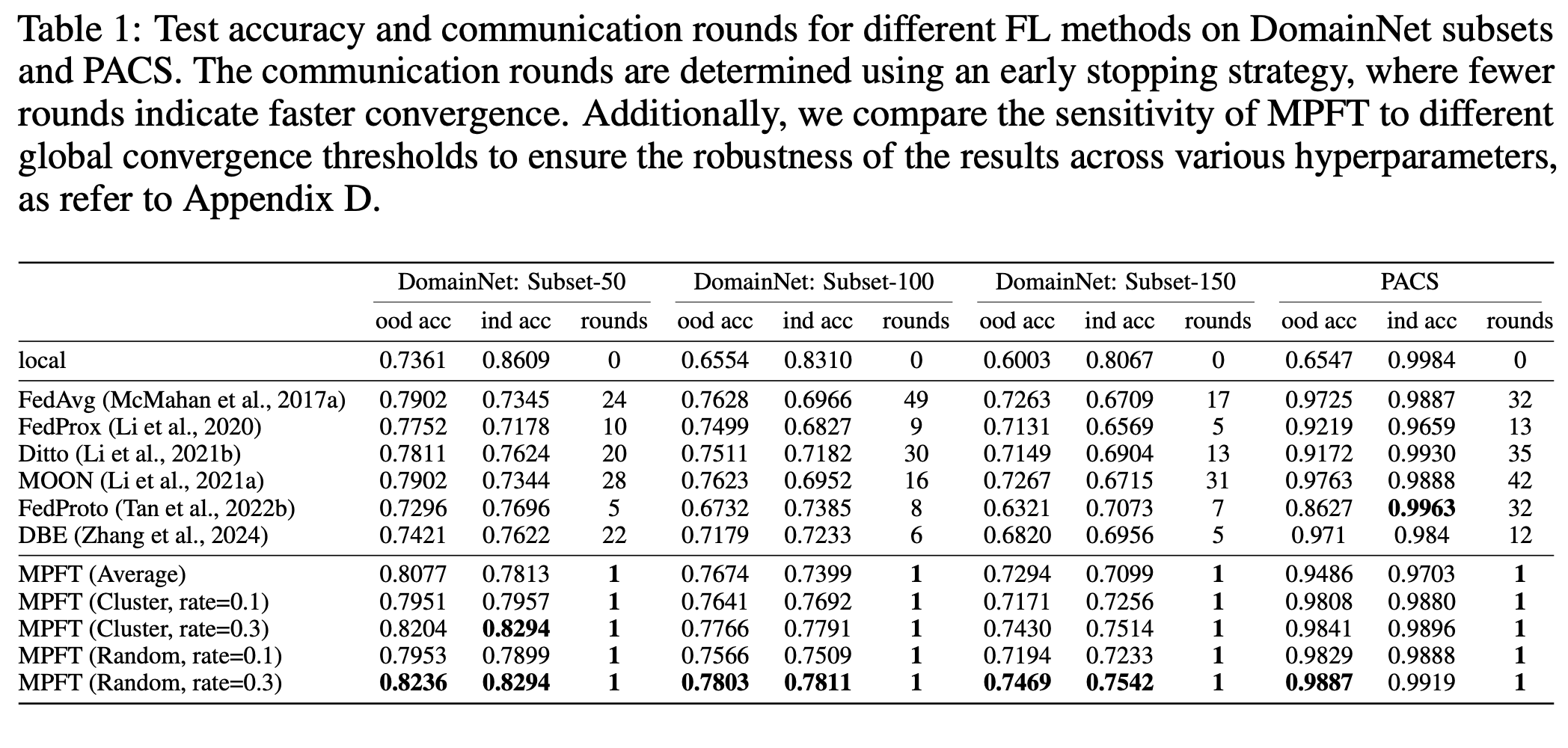
- Compared with FedAvg, FedProx, MOON, Ditto, FedProto, and DBE on DomainNet and PACS, MPFT consistently achieves higher in-domain and out-of-domain accuracy.
- Notably, MPFT converges within one communication round, drastically reducing computational and communication overheads.
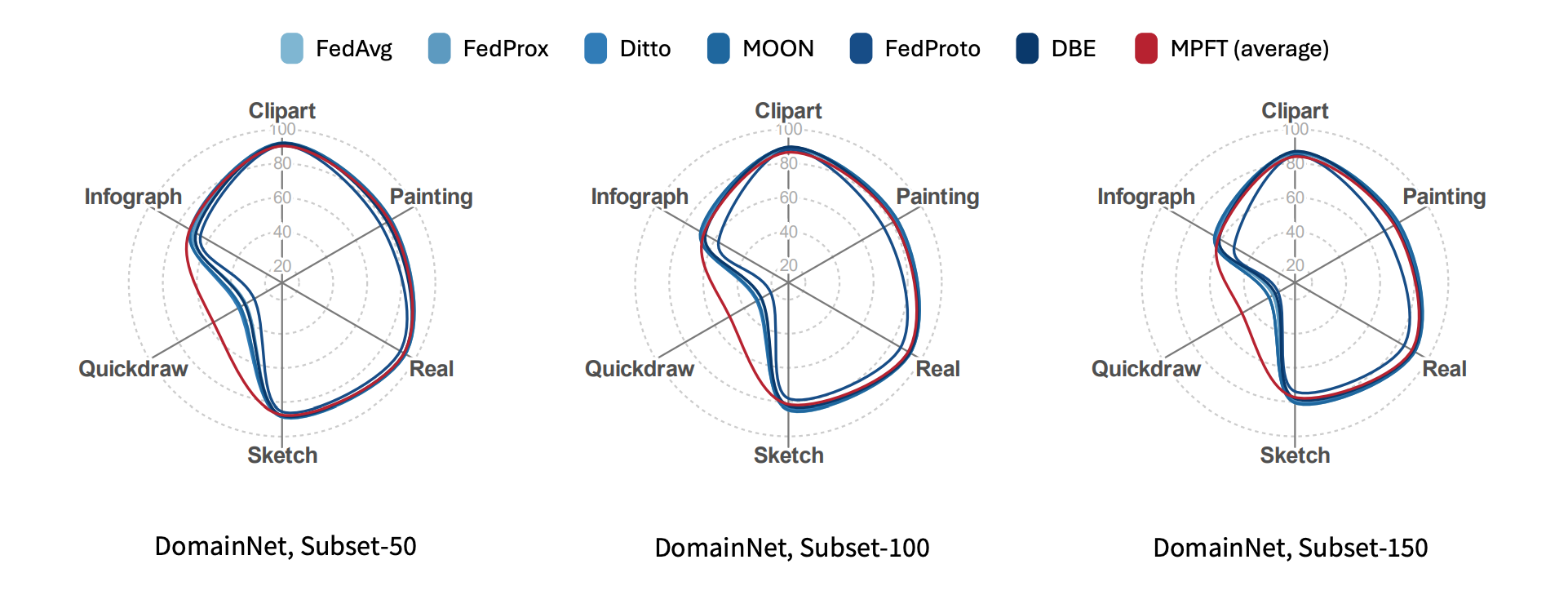
Performance on each domain
- Per-domain analysis via radar charts shows MPFT maintains more “balanced” performance across distinct domains.
- It avoids large performance drops in certain domains and achieves good overall fairness in heterogeneous distributions.
Impact of multi-domain differences on performance
- Even if each client contains mixed data from multiple domains, MPFT still outperforms other methods.
- As domain heterogeneity diminishes, the performance gap to baselines narrows, but MPFT remains strong.
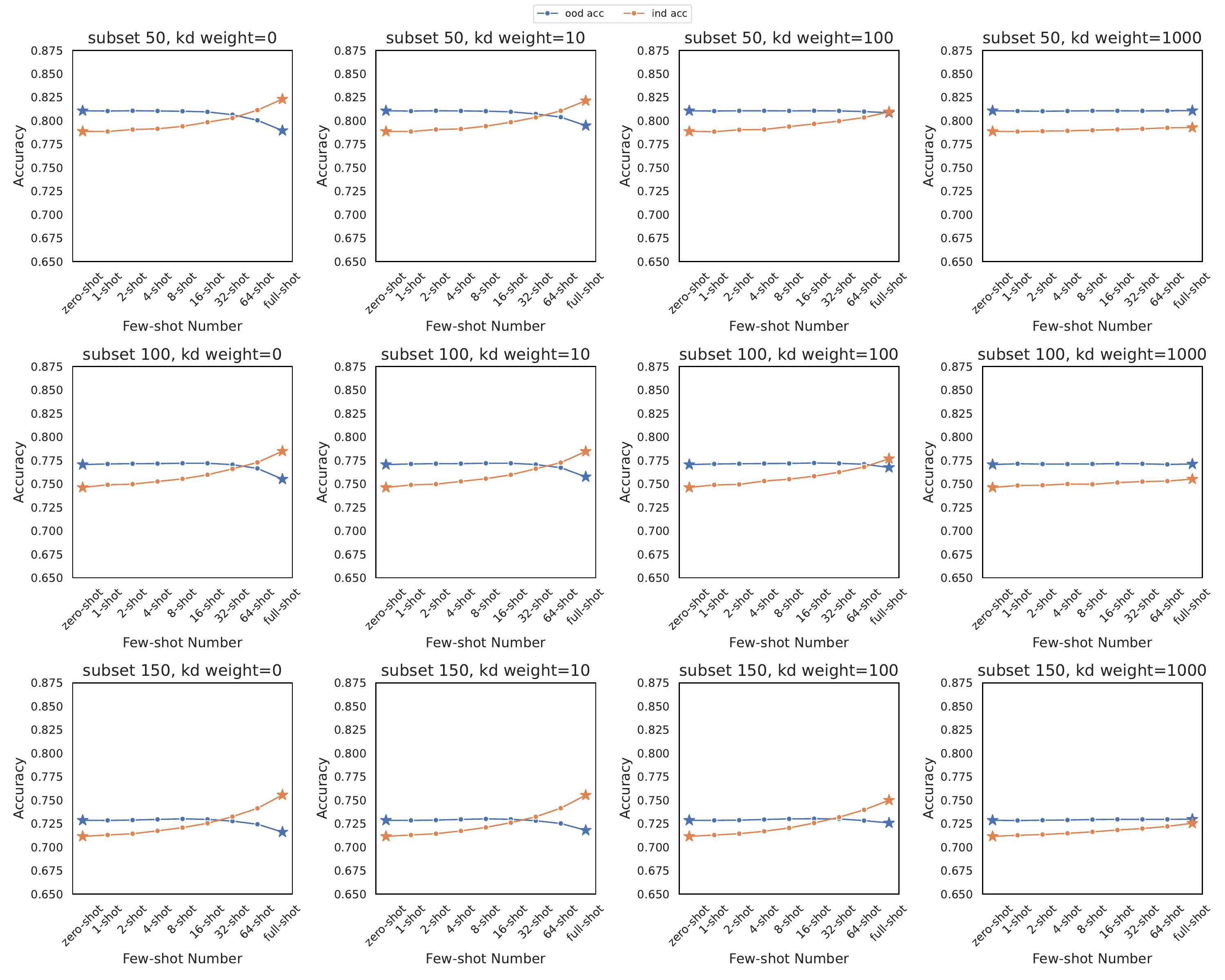
Performance with local adaptation
- When few-shot local data and KD are employed, clients can improve in-domain accuracy without severely sacrificing out-of-domain accuracy.
- Proper KD weighting strikes a balance between preserving global knowledge and optimizing local performance.
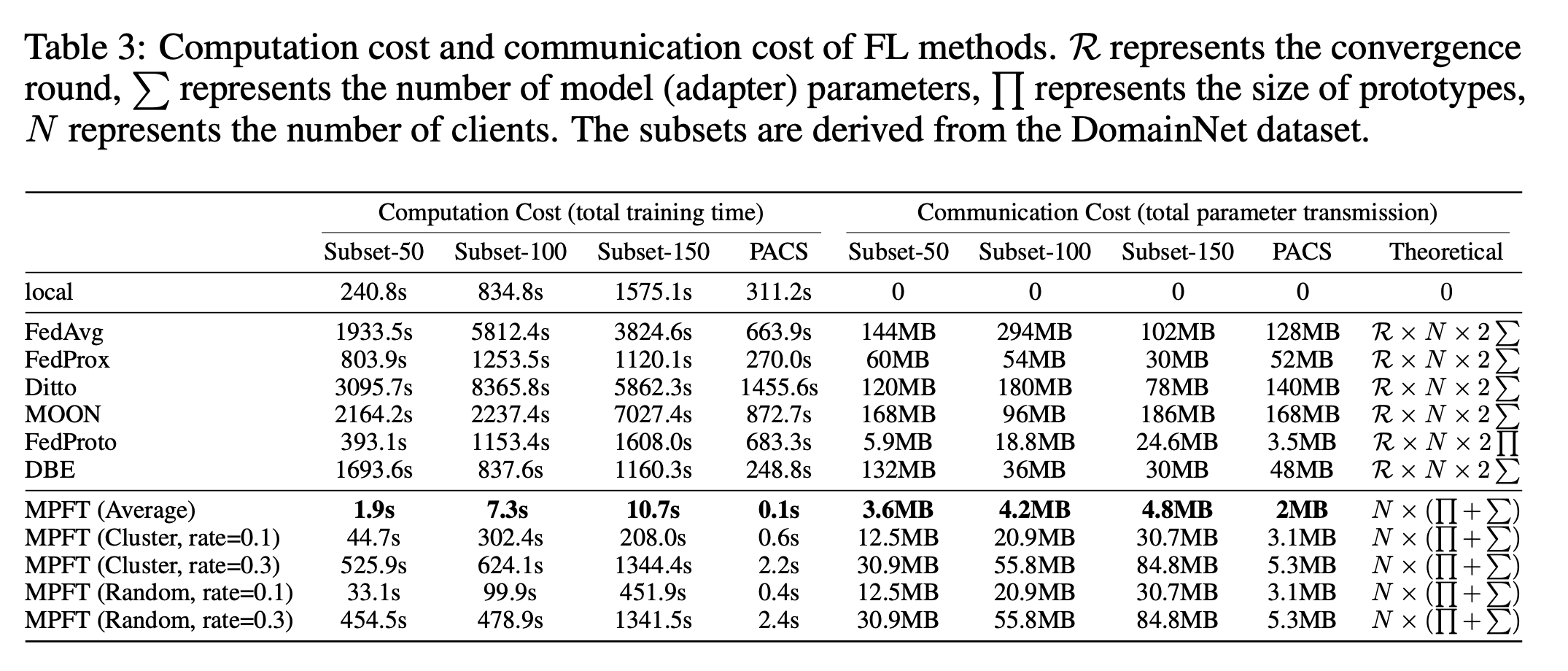
Communication and Computation Analysis
- MPFT requires only one communication round to train the global adapter, significantly reducing communication costs.
- The global adapter is lightweight and can be distributed to clients with minimal computational overhead, making it suitable for resource-constrained environments.
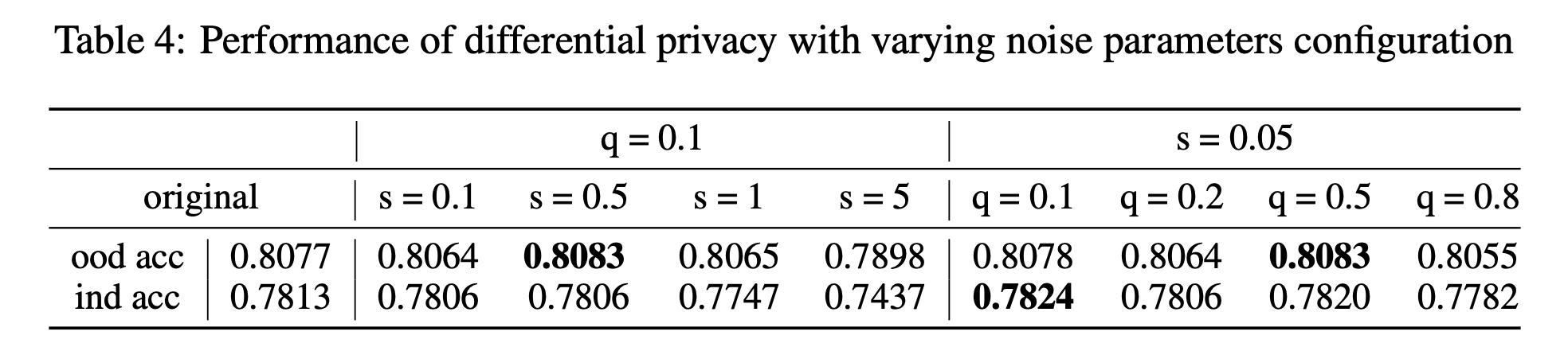
Privacy Preservation Analysis
- MPFT applies differential privacy (via Gaussian noise) to client prototypes before uploading to the server, preventing adversaries from inferring raw data.
- Experiments with a feature space hijacking attack indicate that reconstructing the original images from shared prototypes is extremely difficult, even with knowledge of the pretrained encoder.
- Adding moderate noise can also mitigate overfitting and, in some cases, improve robustness without significant performance loss.
Convergence Analysis
- The paper provides a theoretical analysis under non-convex conditions, showing that prototype-based fine-tuning converges in expectation.
- With appropriate learning rates and bounded prototype divergence, the loss decreases monotonically, ensuring convergence to a stationary point.
Conclusion and Future Work
Conclusion
- MPFT addresses the shortcomings of naive parameter averaging in FDA by training on aggregated multi-domain prototypes.
- It achieves high out-of-domain performance while maintaining strong in-domain accuracy, requiring only a single round of communication for the global adapter.
- It is lightweight, privacy-preserving, and empirically robust to domain heterogeneity.
Future Work
- Prototype Quality: Investigate improved prototype generation and better pretrained backbones, especially when within-class data variance is large.
- Advanced Privacy: Explore stronger defenses against membership or attribute inference attacks while maintaining high performance.
- Real-World Extensions: Adapt MPFT to more complex domains and tasks, such as financial fraud detection or clinical data analysis, where multi-domain data are prevalent.
Citation
@inproceedings{
zhang2025enhancing,
title={Enhancing Federated Domain Adaptation with Multi-Domain Prototype-Based Federated Fine-Tuning},
author={Jingyuan Zhang and Yiyang Duan and Shuaicheng Niu and YANG CAO and Wei Yang Bryan Lim},
booktitle={The Thirteenth International Conference on Learning Representations},
year={2025},
url={https://openreview.net/forum?id=3wEGdrV5Cb}
}